The State of IBM i Storage
More than worrying about the information currently stored in their data center, administrators have a bigger problem on their hands: the immense volume and rapid growth of data they will need to store in the future. IDC’s Data Age 2025 study exposed the realities of the upcoming challenge:
- 16.1 zettabytes of data were generated in 2016
- Worldwide data growth will explode 10x to 163 zettabytes by 2025
- Traditional productivity data and embedded data (like IoT) are especially on the rise
- Embedded data will constitute nearly 20 percent of all data created by 2025
According to the Harvey Nash / KPMG CIO Survey, 55 percent of CIOs reported an IT budget increase in 2020. But for those companies who choose to invest in more storage hardware, cloud computing, and storage management, the Data Age 2025 projections will eat up much of this budget increase.
Instead, IT leaders should look to curb data growth and control storage costs. This guide suggests best-practice IBM i data storage management strategies and technologies to help reclaim disk space today and budget for future growth. You’ll learn:
- Sustainable strategies for data storage management
- Technology to minimize and move your data footprint
- Automated solutions for ongoing data storage management
Data growth projections are simply too big to ignore. It’s essential that IT teams move away from reactive approaches and adopt a sustainable data storage management strategy. This guide is a great resource to get you started.
Enjoy!
Early Indicators for IBM i Storage Issues

The Library File Structure
The vast majority of ERP, logistics, warehouse management, front office, and financial applications running on IBM i access data in files or tables located in the library structure on IBM i, though some use open source databases utilizing the integrated file system (IFS). While considered the traditional file system on IBM i, the files and tables in libraries are supported by all the most recent SQL enhancements and features you’d expect in a modern database. These legacy applications continue to add data and now—with the ever-increasing emphasis on application modernization—there are newer applications running from the IFS or outside of IBM i that still use the Db2 on IBM i database as the back-end data storage architecture.
It’s great that companies have rediscovered the benefit of IBM i as an enterprise data server. The issue is that it puts additional strain on storage management and architecture and presents challenges with operational requirements such as availability, performance, data backup, and high availability.
Because most IBM i activity occurs in this operational arena, more and more “leftovers” from data migrations, save/restore operations, journaling, log files, and diagnostic troubleshooting are left to linger—sometimes for years—before action occurs due to lack of storage. And with more endpoints creating data on the central data server, the problem is increasing exponentially.

The Integrated File System
When collections of data sets become so large that current storage strategies falter, you might hear about it in the integrated file system (IFS) first. System administrators may admit that it’s getting messy, but they aren’t sure who owns the data, how it’s organized, or where to begin cleaning it. The objects there might be auto-created by your ERP application (think Oracle JD Edwards EnterpriseOne) or a document management application converting spooled files into PDFs. Or perhaps legal documents as part of a case management system.
A built-in component of IBM operating systems since OS/400 R3V1, the IFS integrates several file systems, including libraries, into one and includes basic file and directory management functionality that allows the creation of stream files. Non-IBM i team members will recognize these stream files as PDFs, multimedia files, or Microsoft documents. In the case of open source, these could also be Java, HTML, XML, PHP, or any of the other object types supporting the web environment.
While the IFS grants operators the ability to view objects in a graphical user interface, it lacks the accountability features and predictive capabilities of a more robust storage management solution. It may feel a bit like the “wild west” of data structures. And even though auditing can be turned on, the output comes in the form of raw data that is cumbersome to monitor and manage without third-party tools.

Internal vs. External Storage (SAN)
The number of customers using only internal disk continues to slowly decrease year after year. And while many IBM i organizations still rely on internal disk, the trend toward using external storage area networks (SAN) instead is clear.
There are a few components driving this trend. First, the cost of external storage has come down and solid-state (SSD) arrays are less expensive. Second, the increasing interest in hardware-based replication through PowerHA has offered an opportunity for organizations to efficiently replicate their data off-site for HA/DR. Third, SANs can support FlashCopy and this has been a huge benefit to companies looking to reduce downtime (and object locks) due to backups. Finally, virtualization features of Power9 and Power10 technology has made shared storage even more important, so SAN storage is growing in those data centers.

Cloud Storage
Some companies have moved to a hosted model for their IBM i partition(s) and no longer have IBM Power hardware in their data center. This model makes storage capacity more elastic as the managed service providers (MSPs) would be more than happy to provide you with additional storage and will tell you when you need it. However, this comes with an increase in your subscription pricing and does little or nothing for keeping data growth—and therefore the storage charges—in check and monitored at a granular level. MSPs look at storage at the ASP level, not at the library, directory, or file level.
The good news? Storage serves as a good example of how technology has advanced in terms of both sophistication and cost efficiency. Considering that organizations are dealing with explosive amounts of data growth while also investigating new ways of transforming that raw information into insight, this affordability makes storage out to be the perfect, infinitely scalable IT resource. It should come as no surprise, however, that storage has its limits. Buying or renting more disk space may seem like the quick and easy choice, but there are more effective strategies when considering the long-term implications of data growth.
Best Strategies to Handle Explosive IBM i Data Growth
Two philosophies traditionally govern the way organizations deal with data growth: add capacity or better utilize existing resources.
Both paradigms have challenges, and most organizations will likely benefit from executing a combination of both. More precise analysis divides these paradigms into three strategies:
- Hardware expansion
- Better hardware utilization
- Improved data storage management
To help you face current issues with your disk space, and position you for success against the challenges to come, this guide examines these strategies and rates them from good to better to best, based on efficiency, sustainability, and return on investment.
Add IBM i Storage Capacity

Increasing storage capacity is often the first consideration IT leaders make when faced with physical constraints. One way to add capacity is to simply buy new hardware or pay your cloud provider to allocate more storage. Storage virtualization through VIOS (Virtual I/O Server) and SAN has eliminated the time-intensive task of migrating applications and data as additional virtual disk volumes can be allocated with the click of a button.
Another way to add capacity is to replace existing hardware with newer, higher capacity systems. IBM and other technology vendors have become more conscious of their hardware’s energy footprint, so investing in newer storage devices may also lower the cost of running the infrastructure. Also, more disk is squeezed into a smaller footprint, so housing the storage takes a smaller footprint. But don’t forget to consider the upfront investment every time you need to upgrade.
Consider the prediction that global data will grow 10x what it was in 2016 by 2025. Given this unprecedented, explosive rate of data growth, updating your hardware every time your organization starts running into capacity constraints is not financially sustainable. Relying solely on hardware investments will quickly stretch and surpass IT budgets, and there is an operational limit to how much hardware can be purchased as well.
It is essential to think of total cost of ownership (TCO) beyond the cost of the initial deployment and configuration. The cost of housing servers in a physical location, the additional time it takes staff to manage new servers, and hardware upgrade cycles all play a part in driving TCO. In addition, even extensive hardware investments fail to stop the flood of information and data-rich applications that are making their way into your IT environment.
With data centers already reaching their physical and energy limits, many organizations simply will not have the space to continue scaling out storage hardware in this way, and the “add capacity” strategy fails to address the management aspects of data growth.
Increase Hardware Utilization

Rather than purchase additional hardware, organizations may choose to focus on better utilizing the hardware they already have. This strategy often takes the form of virtualization. IBM i partition technology and PowerVM technology allows IBM Power customers to easily deploy virtualized IBM i, AIX, and Linux partitions or virtual machines (VMs). Deploying several partitions within a single appliance allows you to maximize the computing power of your IT infrastructure and can be used to segment different types of work, such as separating production and test environments.
In 1999, IBM introduced partition technology for IBM Power servers to the IBM marketplace. This technology, combined with the worldwide improvement in communications, allowed IBM i customers to consolidate their footprint from thousands of individual servers to several large servers, each hosting several partitions.
In a traditional VM world, these customers today would see server sprawl and a loss of control over the growth of VMs. But because of IBM i’s work management capabilities, this server can easily segregate workloads by type of work or departmentalize by business or geographic locations. The positive results of partition consolidation for IBM i shops have been hardware security, superior infrastructure, and high availability.
Here are the cons: the server has gotten bigger and data centers are storing vast amounts of data on less hardware. In fact, your entire business might depend on two frames in two different data centers with one hundred partitions that support all of your business users. You might have thousands of customers on these two servers. This means you are managing terabytes of data either through SANs or internal attached disks. It is not unusual to see one server hosting 30 terabytes of data.
New installs of software leave installation packages in both the library system and the IFS. Since 1999, IBM and its vendors have introduced thousands of applications using technologies that require the IFS. More and more vendors, including IBM and open source solutions, put data in the IFS—and that’s just the beginning.
Healthcare and banking industry customers are storing scanned data like PDFs and images. Retail and manufacturing applications are loading parts of their application in this space. Many ERP applications, including SAP, create PDF reports or other data extract formats and store this data in the IFS. The problem for system administrators is that their tools for managing disk space are still from 1999 and earlier.
IBM i virtualization has given us the ability to consolidate the server, and we have done a great job improving physical security and disaster recovery as a result. Unfortunately, many organizations still have not given their staff the right tools to help manage data growth.
Improve IBM i Data Storage Management

While hardware-centric solutions may have been the instant reflex to data storage in the past, they lack two critical components for handling future data growth: discarding unnecessary data and mapping growth trends.
With explosive data growth on the horizon, technology staff will run into severe budgetary constraints unless they work toward maximizing the efficiency and overall value of their procurements. Experts and conventional wisdom recommend the following process for reducing costs associated with storing unnecessary data:
- Understand the true cost of data storage, including expenses related to procurement, ongoing maintenance costs, batch processing, response time, and backup activities
- Collaborate to better connect objectives and strategies on a multi-departmental level
- Reduce the operational costs of infrastructure by making systems more efficient and streamlining business processes
- Incorporate compliance and legal requirements into an information governance framework
A data-centric strategy requires organizations to have this level of visibility over their applications and stored information. Building an understanding of current trends within the storage environment allows IT leaders to better predict their organization’s future needs and reduces the TCO, while maximizing the value gleaned from both existing and new infrastructure investments.
In short, a data-centric solution will continue to provide value regardless of what hardware investments are made or what other factors affect your IT environment.
Best Technologies to Handle Explosive Data Growth
Gaining visibility over information requires a strong alignment between IT practices and technology. There are many technologies you can employ to maximize existing storage assets—and increase the lifespan of your IT investments—including deduplication, compression, storage tiering, and data archival. Each of these technologies can be useful to varying degrees depending on your organization’s IT environment. More important than the individual approaches, however, is how they are implemented together.
Deduplication

Simply put, data deduplication technology eliminates duplicate copies of data. Often used in cloud storage to reduce storage space and upload bandwidth, deduplication is especially effective when used for backup, primary data storage, and wherever flash storage is used.
However, deduplication does have a tendency toward diminishing returns. While it is a fundamental component of any storage management system, the decreased value of the technology can be explained by the fact that it requires a large amount of redundancy between files to yield high returns. In short, if you don’t have a lot of duplicate files, deduplication will not save you a significant amount of space.
Additionally, deduplication can introduce a risk of data loss when dealing with essential data. Because deduplication keeps only a single instance of redundant data, it can lengthen recovery time or even make some files unrecoverable—not an acceptable risk for mission-critical or compliance-related data.
Compression
In IBM i environments, compression is most often used for backups. It is a better option for mission-critical data that must remain always available because it reduces file sizes—rather than deleting—to maximize existing space. Compression focuses on reducing redundancy within the file itself, so total capacity usage is reduced without affecting recovery processes or exposing the organization to a heightened risk of data loss.
The downside to compression is that running the technology itself can use hardware resources and impact overall performance. IBM emphasizes that you consider several factors prior to compression, including processing costs, input/output costs, and the type of data in question. Digital information that contains frequently occurring characters or strings will benefit the most from compression.
Storage Tiering and Data Archival

Reducing total capacity used is only one aspect of responding to data growth. The other critical element is to ensure that space is used optimally. Although compliance and legal responsibilities require that large volumes of information be retained, not all data is created equal.
Storage tiering is the process of automatically migrating data between different systems based on how often it is accessed. Frequently used information should remain in a high-performance storage environment to ensure that user experiences do not suffer while other data should be moved to a lower-performance tier or archived.
For example, solid-state drives typically offer the highest level of performance, but might be too expensive to implement throughout an organization’s entire infrastructure. The files most frequently used would be stored on SSD drives while data that is not frequently accessed would be stored in more affordable spinning disk drives, commodity-class SSD, or cloud storage.
Determining the best overall approach for optimizing enterprise storage in your IT environment requires greater visibility as well as the ability to plan more accurately. Without solutions to analyze existing storage trends—how much a file or group of files grows over time, for example—it’s not possible to evaluate the effectiveness of implemented solutions.
Features Checklist for IBM i Data Storage Management
Implementing data storage strategies and technologies impacts the operations and procedures of every department that relies on that data. IT managers can lead the way and prevent explosive data growth from overrunning their organizations by adopting tools that grant insight into current and future storage needs.
Once you make the decision to take advantage of a professional tool designed for data storage management, do your homework. Be sure the solution you find is scalable, provides superior directory visibility, proactively discards unnecessary data, and maps growth trends. Also, consider how well a vendor’s solutions integrate with each other and with your environment, and define the results you want to see.
What does your data storage management tool need to do?
Your IBM i Data Storage Management Solution
Robot Space is backed by decades of expertise in systems management for IBM Power servers running IBM i. Powering environments from the largest, most complex IBM i and IBM i-connected systems to the medium and small shops that rely on IBM i to store their critical data and applications, Robot Space leverages the stability and feature-rich IBM i platform with custom, flexible scripting, intuitive graphical interfaces, and mobile capability, plus a security layer to satisfy your corporate policies and IT audits to bring you a comprehensive feature set that automates data storage, monitoring, and cleanup.

Robot Space eliminates wasted space before it happens. It constantly monitors your ASPs, IASPs, libraries, IFS objects, and active job temporary storage levels, so you know exactly where explosive data growth is wreaking havoc. Your operators can predefine as many as three size and growth thresholds to continuously enforce maintenance rules.

Cross a threshold, kick off an automated cleanup process. Robot Space performs over 20 disk space cleanup duties automatically, including archiving or deleting unused save files and journal receivers. Discarding unnecessary data keeps your disk drive use at normal and stabilizes your system performance, so you avoid spikes that force unplanned downtime. Collection statistics also help you identify who is using what on your IBM i by investigating down to the object level.
Based on historical data, Robot Space helps you map growth trends and predict your future disk space requirements, making it easier for you to plan and budget. You also can compare library and object collection statistics to determine growth from one collection to the next.
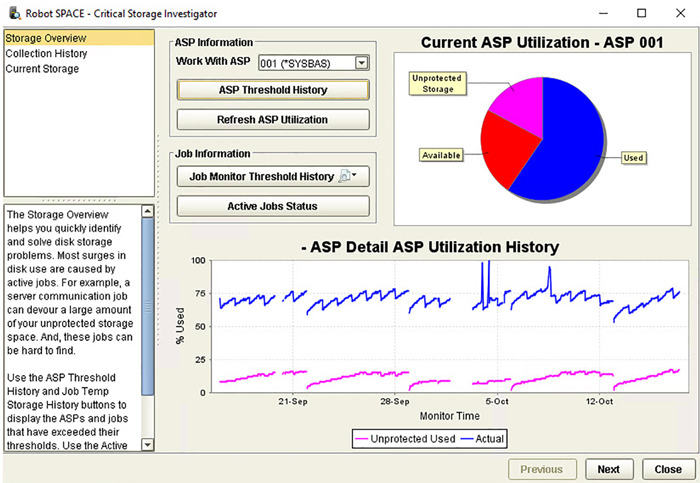
The Critical Storage Investigator (CSI) problem-solving feature in Robot Space is your best weapon against explosive data growth. It helps you quickly find disk storage problems by using a logical progression, displaying real-time ASP storage, detailed ASP growth history, ASP threshold history, active job storage history, and the active job status. You can assess your current storage status at a glance or, if necessary, drill down deeper to see precisely when and why storage thresholds were exceeded.
When a critical storage condition exists, Robot Space works with Robot Alert to send a message to the device you designate—cell phone, laptop, or tablet. Your operators can send and receive texts or emails from anywhere in the world, giving them freedom while keeping an eye on the real-time performance of your system.
Next Steps: Clean Up Your IBM i Disk Space Today
Data centers are already running out of data storage space, and explosive data growth is on the horizon. Management will face budget problems if they don’t adopt solutions to curb data growth and control storage costs. By actively monitoring and adopting tools that provide trend visualizations for storage pools, IT managers are better equipped to predict future needs and make more strategic hardware investments.
IBM i data storage management using automation tools is the most viable option when facing explosive data growth. This strategy is highly scalable, providing value regardless of other IT changes. While some IT leaders have been hesitant to turn to data storage management for fear that these strategies would be more complicated and more expensive to implement than new infrastructure, rampant hardware investment is not a sustainable solution for the long term. You will likely find that you’re running out of space sooner than you think.
What worked yesterday won’t work tomorrow. Choose a sustainable IBM i data storage management solution and start cleaning up your disk space today.
Try Robot Space free for 30 days!

