As you collect more information, your relational database files continue to grow and you’re faced with a challenging issue: how to handle all of that information efficiently and accurately, and how to overcome the obstacle of mining and delivering useful information without bogging down the system.
Partition files are the solution to BIG DATA on IBM i because of:
- Improved manageability for large tables
- The ability for various data partitions to be administered independently (able to backup and restore selected data partitions instead of the entire table)
- Increased query performance through data partition elimination
- DB2 optimizer is data partition aware; only the relevant data partitions are scanned
- Fast online data roll-in / roll-out
- Can easily add or remove data partitions without taking the database offline
- Better optimization of storage costs
- DB2 9 allows you to optimize your overall storage costs and improve performance
- Larger table capacity
- Greater index placement flexibility
Big Data: this term covers a lot of ground. With no definitive dividing line based on file size, data type, number of records, or job requirements, how do you know if you’re doing big data? Ask yourself: has the size or speed requirements of any new analytic initiatives put serious strain on my existing IT infrastructure? Most organizations could say yes because big data is everywhere. For example:
- IBM estimates that 90% of the data in the world today was created in the last 2 years alone
- 10,000 payment card transactions are made every second around the world 1
- In 2009, over 152 million text messages were sent 2
- In 2011, US healthcare data alone reached 150 exabytes of data, and that number is expected to double each year. McKinsey estimates that the industry could save $300 billion annually by leveraging big data. 3
SEQUEL allows you to work with your big data efficiently and accurately, allowing users to get the information they need, how they need it, and when they need it.
With SEQUEL you can:
- Explore your data efficiently using the faster SQE (SQL Query Engine)
- Query data locally on the IBM i or on other systems
- Query multi-partitioned files
- Email or display live, current, dynamic data
- Create or send results as a text, Excel, PDF, HTML or other PC documents
- Display data from a green screen or graphical interface
- View data from a browser or mobile device with SEQUEL Web Interface
How can SEQUEL easily query multi-partitioned files with millions, billions, and trillions of records?
SEQUEL can scan multi partition tables (files) with a single SEQUEL View. Do you have a large number of records? Are you concerned about efficiency? No problem. SEQUEL uses the new, faster SQE to help gather the selected records quickly. With table partitioning and SEQUEL, using a server parameter of *LOCALSYS allows SEQUEL to use the SQE (SQL Query Engine). You can actually build ONE query that selects data over multiple members of a partitioned table at the same time.
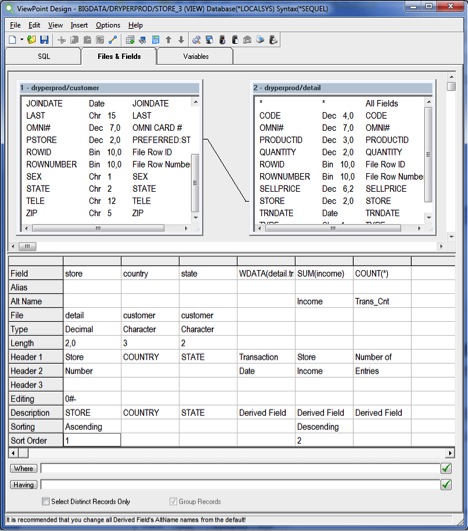
Example: SEQUEL’s graphical interface (SEQUEL ViewPoint) allows users to simply drag-and-drop, then double-click to build the view. With the database or server parameter set to *LOCALSYS, it makes scanning ALL the records from ALL members fast and simple.
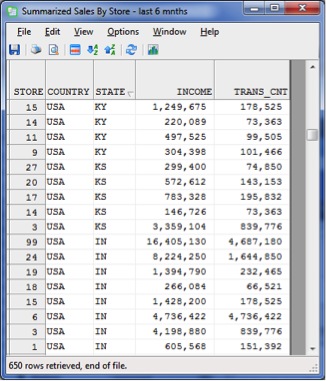
Below, we are summarizing two files, which are growing daily. One file alone has about 13 million records, which translates into a usable summary result of 650 records. From here, the user can drill into the detailed information.
Image 1 – Database set to *LOCALSYS
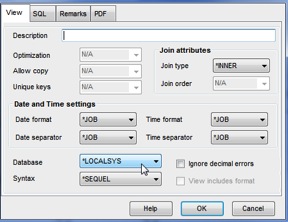
Image 2 - The View Definition
The results: All records from all table partitions returned and summarized.
With any combination of big data, SEQUEL can deliver the results you need, how and when you need them. Partition files can easily handle your big data needs on the IBM i, but you’ll need a tool to mine the data, deliver useful information to the user, and run efficiently using a fast query engine like SQE. To handle your big data partition files, you’ll need SEQUEL. See how SEQUEL makes your big data access fast and easy with minimal setup time or struggle.