Introduction
So what do you call yours? AS/400, iSeries, i5, IBM i, Power Systems or maybe you long for the initial code names for the machine namely Silver Lake or Olympic. For the record, mine is called an IBM i although deep down it will always be an AS/400.
The machine itself has retained its core, single-level storage architecture which is underlined by the fact that, providing observable information is available, code written in the early days still functions today. I’m not sure how many other platforms, if any, can boast that.
Irrespective of what yours is called and what code you run on it, I would hazard a guess that at some stage spool files (or to give them their correct grammatical name spooled files) have caused you a headache in that the way they appear to multiply seemingly without any rhyme or reason. Where on earth did they all come from, are they still required and more importantly can I delete them? In many industries, financial records have to be kept for 7 years but what constitutes a financial record?
Is it a report created by somebody working in Finance, or created by the Accounts package installed or maybe any its report that simply has a number or a total on it? Who knows? So what tends to happen is that IBM i Administrators err on the side of caution and leave them. Quite often reports will remain on an output queue until somebody inadvertently deletes them or clears the queue by mistake when trying to free up some disk space.
What then follows is what I call a tumbleweed moment which can last anything from minutes to months or until somebody needs or asks where the spooled files are. Of course all knowledge of the incident is universally denied due to the fact that the spooled files cannot be restored, retrieved or brought back from a handy recycle bin. Wouldn’t it be great if the IBM i had a <CTRL + Z> undo facility? Maybe in the next release, hey Rochester?
This guide explores functionality outside of the standard operating system and IBM Licensed Programs that are available to perform on spooled files that will demonstrate how spooled file management can be brought into the 21st century, bringing with it both business and IT benefits.
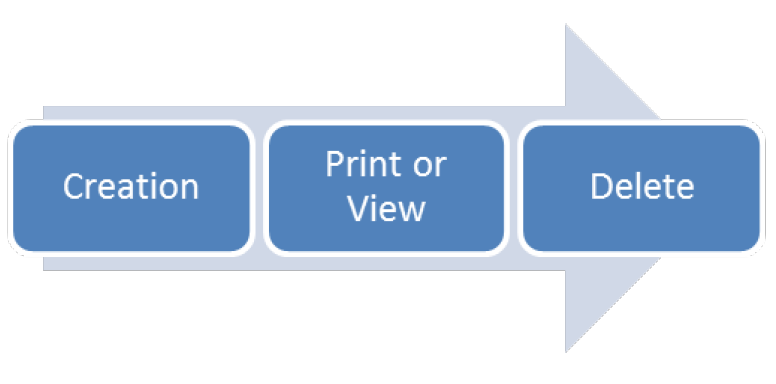
The Lifecycle of a Spooled File
In many IBM i shops, the humble spooled file leads a simple life. It gets generated by a user or an application and is then either printed or viewed before being left on an output queue until one day it’s deleted. Although the excellent Backup, Recovery and Media Services (BRMS) Licensed Program offers a reasonable way of saving and retrieving spooled files there is a lack of flexibility to do other things from what is a very good Backup and Recovery solution.
It has only been in relatively recent times where you’ve actually been able to save and restore spooled files using native IBM i commands. Chargeable Licensed Programs such as BRMS, as supplied by IBM, offer slightly more but the lack of flexibility makes these options limited.
At the operating system level there is of course the ability to offload spooled files to an Independent or User ASP to keep them separate from the System ASP. Although this is a viable option, it doesn’t move the spooled file from the IBM i or into an alternative, more useable format and therefore the same housekeeping challenges are still very evident. The only thing you’ve done is to move the problem onto alternative IBM i disk, which admittedly may be all you’re trying to achieve anyway. During my extensive travelling and working in Data Centers across the globe, I very rarely come across User or Independent ASP’s being used, in fact I’d go as far as to say that they are utilized in less than 5% of companies.
If a spooled file could talk (bear with me, it will be worth it) what would it say on its death bed? Would it remark on how fulfilling its life had been that life had exceeded all expectations and that it was happy to slip away? Or would it regret missed opportunities to shine and continually talk about the good old days when it was created? Being a gambling man I wager it would be the former. So how can you help the next generation spooled file so that it doesn’t suffer the same regrets as its older relatives and leads an exciting feature-rich existence?
Welcome to the 21st Century
In this section I have described four scenarios which may be prompting you to “do something” with spooled files on your IBM i. Things like disk space management, archiving, search and retrieving, distribution and sharing spooled files. The way you handle these can have a direct benefit to both the business and the end user and best practice disciplines make a valid contribution to IT efficiency.
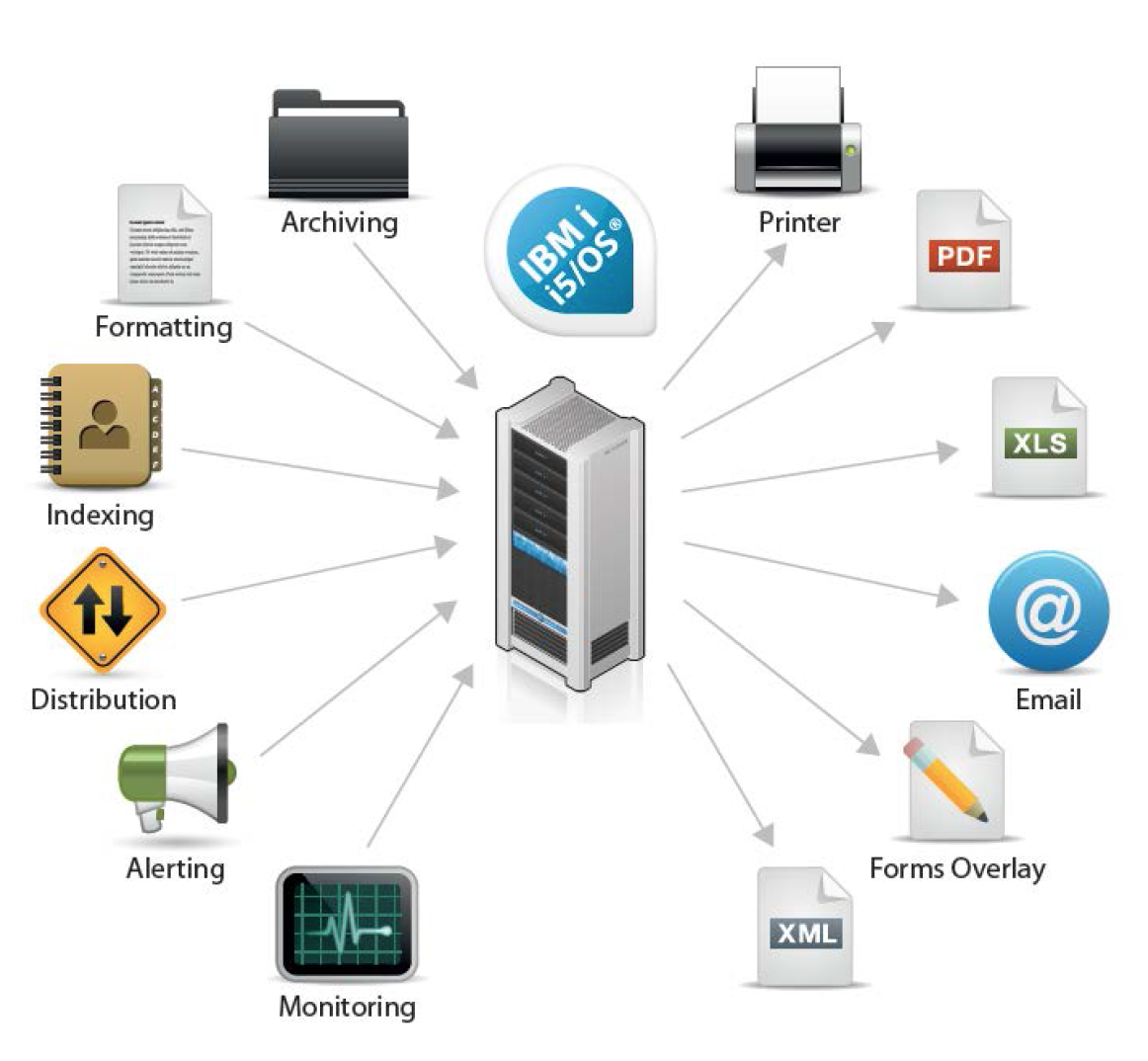
Disk Space Management
IBM hardware has always thought to be priced at the premium end of the market, underlined by the popular axiom “nobody ever got fired for buying IBM”, that still echoes in the offices of decision makers across the world today. IBM i disk is relatively expensive as is any footprint into the market of SAN’s and external storage, so what can you do to reduce the space that spooled files consume on your midrange machine? You have three real choices here; delete, migrate onto cheaper disk or archive. Let’s look at each of these in turn.
DELETE
Many Administrators periodically elect to delete spooled files at what looks to be seemingly random times. Often when IT staff have time on their hands (yes, I know this is rare), or perhaps when they have noticed that the disk pace utilization percentage has crept up. The QEZJOBLOG and QPRINT are the output queues that Administrators focus on initially.
To reduce disk space, they may decide to move spooled files onto departmental or user queues or delete them completely. The deletion of a spooled file may not be based on any logical decision other than a ‘gut feel’ that they are no longer required. For example, huge job logs may indicate a looping job or files created by ex-employees.
Then you could justify a snap decision that they are no longer needed. I discuss the remedy to this situation later when I talk about best practice archiving. The removal of these spooled files isn’t necessarily going to have an immediate impact on the disk space utilization. Special consideration should be given to the system value QRCLSPLSTG and the operating system command RCLSPLSTG which denote and control how quickly the internal database members are removed following the deletion of spooled files and therefore when the space becomes available again.
I have worked on systems where there have been literally thousands of output queues with hundreds of thousands, sometimes even millions of spooled files on them. There are some big spooled files out there, some in excess of a million pages. Believe me, manually managing this volume of spooled files on these systems and probably on yours too is a thankless and tedious task.
What happens though if an important spooled file, for example a monthly sales summary report, is inadvertently deleted, either by an Administrator or maybe a user, and somebody requires access to it in order to produce a report for the Auditors? (Whoops!) With no audit trail, you have no easy way of recreating or recovering the spooled file which will probably mean a restore before the report can be re-run. Failing that, the figures from the missing report may have to be obtained from a number of other reports or worse still, guessed.
KEY RECOMMENDATIONS
The deletion of spooled files has its place, but should not be done on mass without specific rules in place based on the content and age of the spooled file. There should always be an audit trail that clearly shows when and why a spooled file has been chosen for deletion.
If you want to have a complete audit trail of the deletion or migration of your spooled files so you’re never caught out answering the question “Where did they go?”, then you need an automated solution in place. One such example is the Document Management System by Halcyon Software. Create rules which set user-definable criteria like age, size and content of spooled files such as invoices, delivery notes, dispatch notes, pick lists, purchase orders etc.
MIGRATE ONTO CHEAPER DISK
For example, export your spooled files to a less expensive platform, such as Windows®. This option not only negates the risk of inadvertently deleting a spooled file that is possibly required at a later date but also removes it from expensive disk and onto cheaper and potentially more accessible disk to your business. To get the spooled files onto Windows managed disk from the IBM i you need to setup the NetServer File System (QNTC) which is located under the root of the IBM i IFS for which there are several caveats;
- The IBM i and the Intel share must be on the same domain
- QNTC uses the NETBIOS protocol; therefore it can never see servers that are on another segment
- The Intel server and domain names must be 15 characters or less
- The share name must be 12 characters or less in length
There are many articles on the internet including one in IT Jungle, that describes step by step how to setup QNTC. Once this has been configured, you’ll have access to a Windows share from an IBM i command line by referencing;
/QNTC/ComputerName/ShareName/Path
Additionally, you can elect to tidy up or delete the spooled file in question following a successful copy to the Windows share.
KEY RECOMMENDATIONS
Of course, like any other form of spooled file processing, it is imperative to have a record of the processing that has been performed. Halcyon’s Document Management System provides a visible audit trail for every single spooled file processed. The third important action I mentioned earlier was archiving spooled files to reduce disk space. One suggestion I can pass on from my experience is to keep 30 days’ worth of key business data on the system, within spooled files but elect to keep older versions in archive files. In fact, the archiving of spooled files is such a large topic of discussion that I have explored this more fully in the section below.
Archive, Search and Retrieve
Many organizations have fully justifiable reasons for their need to keep spooled files on the system. Sometimes this is legal requirement, at other times this is purely the historical way the business works. Whatever the reason, simply leaving them on the IBM i shouts inefficiencies all round. The business will waste many hours attempting to locate spooled files before viewing them, simply to verify that they are the correct ones. An added pressure might be that a search has to be completed when a customer is waiting on the phone for information contained in the spooled file. In addition IT Administrators have to manually age the spooled files (move them based on their creation date) to other queues and have to organize the saving of them over many generations in case the originals are ever lost.
If we step back and take a look at these business and operational demands, we see that it’s all about having the ability to archive search and retrieve essential information very quickly. Halcyon’s Document Management System addresses these three requirements as well as many others and makes a noticeable contribution to business and IT efficiency. This is where an automated solution becomes very powerful and necessary to ensure that the business, your users and your customers rapidly obtain the relevant information they need, when they need it.
ARCHIVE
With the right solution in place, flexible rules can easily be configured and definitions can be set to automatically perform actions on spooled files based on many variables including their age, size, created by user /program, name and status. The spooled files are then archived without the need for any further user intervention. Each “set” of archive files can be kept online for a specific number of generations or until they reach a certain age before being systematically being offloaded to tape.
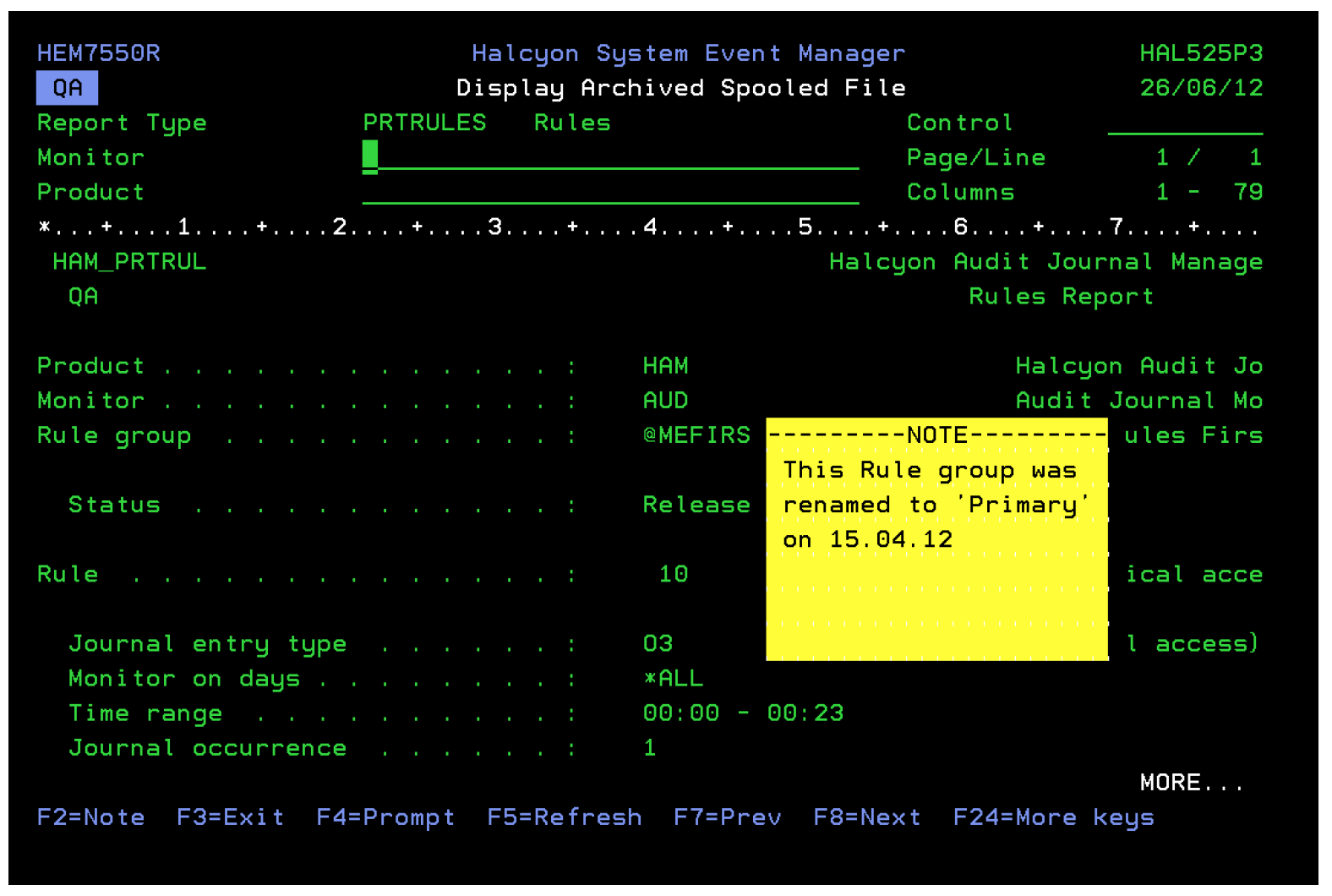
Archiving gives you the opportunity to delete the original spooled file therefore saving valuable disk space. Additionally, by using intelligent indexes you open up the archived spooled files in a far more flexible way than is possible with native spooled files. The screenshot below shows an archived spooled file along with a “sticky” note, used to highlight special instructions to users that view that file. The sticky note is visible both on the green screen and a web-based, graphical user interface.
SEARCH AND RETRIEVE
Once you have archived spooled files, made up of the original spooled files, the searching process has never been easier. Indexes can be created (and even linked for ultimate flexibility) that provide the user with the ability to search across the archives looking for some specific text or patterns of text. The searching is extremely quick often locating the required data in a sub-second. Compare this to the convoluted method of having to first find the correct spooled files then having to manually view each and every spooled file until the specific data is located.
Experienced IBM i users will be happy to use a traditional green on black 5250 display session but it is ideal to provide other users in the organization with a browser-based, intuitive front-end, eliminating the requirement for all key staff to have specialist IT skills to retrieve important information from the green screen environment. One such example is the web-based front-end of Halcyon’s Document Management System for IBM i. The GUI runs in a standard web browser and comes with the same functionality as the native green screen plus it also has the ability to retrieve any required spooled files, reprinting if desired over a designated overlay.
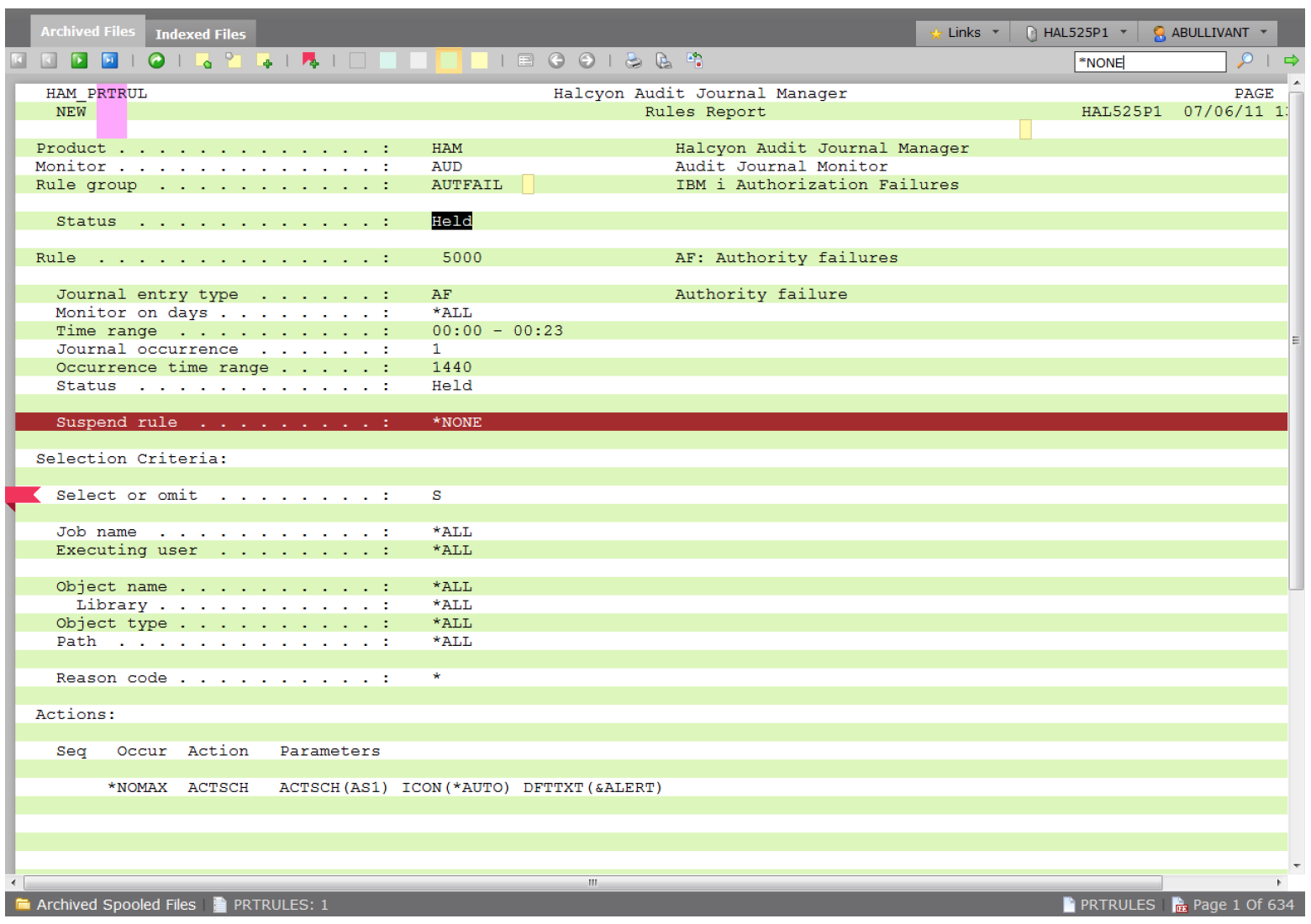
Once you have quickly located the required spooled file(s), the chances are you’ll want to retrieve them and potentially send them to your customer or other users. The GUI contains template overlays in addition to an overlay designer which can be customized to include logos and makes the reprinting of original reports very quick, modernizing and simplifying a traditionally labor-intensive activity.
KEY RECOMMENDATION
One way to gain real IT efficiency is to empower your staff to access and export essential business information without impacting on your time as an IBM specialist. Consider evaluating automated solutions to improve the flow of business information.
Distribution
For many IBM i shops, the distribution of spooled files equates to either printing the reports locally, and manually sorting them prior to dispatch or routing them to the correct output queue so that they are printed at a location close to the intended recipient. Many of these reports are historical (some may no longer be required) yet they still get produced on a regular basis by jobs or processes that still run. Sometimes it’s often easier to leave them in place than secure development resources to make changes to the code. Often the intended recipient no longer works for the company or maybe just requires a subset or a summary of the report. I’m staggered how much paper is still wasted globally despite everybody having much more environmental awareness. Surely there is a more sensible approach?
The nature of your business coupled with the physical location of your offices has a bearing on which of the following options will work best for you when assessing how to distribute your spooled files in the most efficient manner.
SEGMENT AND BUNDLE
Designed for situations where you’d like to distribute and potentially merge multiple segments (sections) from more than one spooled file to produce a new tailor made spooled file in the form of a bundle. These newly formed bundles can be printed, emailed (in various formats), copied to the IFS or exported to a Windows share.
Segmenting and Bundling is an important feature of Halcyon’s Document Management System that greatly improves efficiency as the reports generated contain exactly what the recipient requires. Money is saved on paper and the environmental benefits are there for all to see.
KEY RECEOMMENDATIONS
There are a few other solutions on the market which have this functionality. I recommend you adopt a segmenting and bundling approach to streamline and modernize spooled file distribution within your organization.
Nowadays spooled files are not printed but are converted to PDF’s and emailed. For ease, I’d seriously recommend that the converting and emailing is performed natively on the IBM i – any additional servers or links in this process increases unnecessary complexity. Many solutions offer the choice in spooled file conversion and are likely to offer PDF and Text based emails.
For those reports that do not require printing, the option to email them introduces further efficiencies; reports can be emailed automatically to individuals or logical groups of people, for example you could email the last page of the monthly sales report to all Sales Managers.
Having the ability to alert a user via email (or even SMS) that the document they’ve been waiting for is now ready for them is an added bonus.
With the numerous options available to users that can be taken on spooled files which have been discussed in this Whitepaper, printing should only be considered to be a last resort.
Conclusion
Your investment in IBM i has been made, probably many years ago and although operating system enhancements are regular, many of the advancements are simply not used by the general IBM i community. The performance improvements are always welcome as are the security enhancements designed to keep potential intruders at bay but what I don’t see are many new features being made available that would increase the end user or administrator’s perception of the machine. Many people view the IBM i as “legacy hardware” but with the right tools and applications in place it can be turned into a cornerstone of your strategic infrastructure for years to come. Harnessing the traditional strengths of the IBM i with a scalable, automated solution can significantly modernize the management of your essential business information, save you time and the company money.
Call us at 800-328-1000 or email [email protected] to set up a personal consultation. We'll review your current setup and see how Fortra can help you achieve your automation goals.